
Di staff
Cos’è e come nasce l’intelligenza artificiale
Prima di addentrarci nell’analisi delle tecnologie su cui si basa l’intelligenza artificiale cerchiamo di darne una definizione e di illustrare, per punti estremamente sintetici, la sua storia.
Definizione di intelligenza artificiale
Iniziamo subito togliendo ogni speranza a chi cerca una definizione univoca e condivisa della locuzione “intelligenza artificiale” perché è un concetto che comprende un numero molto ampio di argomenti che afferiscono a differenti discipline, dalla neurologia all’informatica, dalla neurobiologia alla neurofisiologia (e in genere tutte le discipline che studiano il cervello umano) alla matematica e così via. Per cui, più si cerca di darne una definizione scientifica omnicomprensiva più si è costretti a semplificarla (per non tralasciare aspetti fondamentali a seconda del punto di vista preso in considerazione) e ne rimane una definizione apparentemente banale: la disciplina che studia la progettazione, lo sviluppo e la realizzazione di sistemi in grado di simulare le abilità, il ragionamento e il comportamento umani.
E allora, per cercare di comprenderne gli ambiti di azione, è necessario rifarsi alla storia di quella che solo in anni più recenti è considerata una vera e propria disciplina scientifica, quando essa è comparsa per la prima volta e da dove deriva.
Quando nasce l’intelligenza artificiale e come si è evoluta
In questo capitolo dedicato alla storia dell’AI sintetizziamo in modo schematico i principali snodi evolutivi e, dato che stiamo parlando di sistemi che simulano il comportamento dell’essere umano, lo facciamo utilizzando come metafora per il racconto proprio la vita umana.
La gestazione dell’AI
- Le prime scintille che porteranno alla nascita di questa disciplina sono quelle accese nel secolo che ha rivoluzionato la scienza e dato inizio alla scienza moderna, il 1600 (anche se convenzionalmente l’anno di inizio della rivoluzione scientifica è considerato il 1543 con la pubblicazione del De revolutionibus orbium coelestium di Niccolò Copernico). È nel XVII secolo infatti che vengono costruite le prime macchine in grado di effettuare calcoli automatici (Blaise Pascal, Gottfried Wilhelm von Leibniz).
- Charles Babbage con la sua “macchina analitica” che anticipava le caratteristiche dei moderni calcolatori nella prima metà dell’Ottocento e naturalmente il lavoro di Alan Turing, considerato il padre dell’informatica, a partire dalla seconda metà degli anni ’30 del secolo scorso rappresentano il liquido amniotico nel quale la gestazione dell’intelligenza artificiale prosegue.
- È però nel 1943, con il lavoro del neurofisiologo Warren Sturgis McCulloch e del matematico Walter Harry Pitts, che questa gestazione si avvicina al termine: prima di tutto i due scienziati, basandosi sull’osservazione neurofisiologica, teorizzano che i segnali tra due cellule siano caratterizzati da un comportamento di tipo esclusivo dove la trasmissione del neuroimpulso può essere solo completa o nulla (accesa/spenta); assimilando quindi il neurone a un sistema binario, McCulloch e Pitts mostrano, con un modello matematico, come dei semplici neuroni possano essere combinati per calcolare le tre operazioni logiche elementari NOT, AND, OR. È da questi assunti che nasceranno le reti neurali artificiali e che la scienza giunge a partorire l’intelligenza artificiale.
La nascita dell’AI
- La locuzione “intelligenza artificiale” ha una data di nascita precisa: viene utilizzata per la prima volta dai matematici e informatici John McCarthy, Marvin Minsky, Nathaniel Rochester e Claude Shannon in un documento informale del 1955 per proporre la conferenza di Dartmouth che si terrà l’anno successivo e sarà considerata la vera e propria “sala parto” dell’intelligenza artificiale: viene infatti qui presentato il primo programma esplicitamente progettato per imitare le capacità di problem solving degli esseri umani.
L’infanzia dell’AI
Il periodo dal 1950 al 1965 è di grandi aspettative e, come l’osservazione di un bambino che inizia a parlare o a camminare, le prime attività intorno alla neonata disciplina sono entusiasmanti.
- Nel 1950 Turing propone il suo famoso “gioco dell’imitazione” nell’altrettanto famoso articolo Computing machinery and intelligence, nel tentativo di rispondere alla basilare domanda: le macchine possono pensare?
- Nel 1958 lo psicologo Franck Rosenblatt propone il primo schema di rete neurale, detto Perceptron (percettrone), pensato per il riconoscimento e la classificazione di forme e che consiste in un’entità con un ingresso, un’uscita e una regola di apprendimento basata sulla minimizzazione dell’errore.
- Nel 1958 McCarthy sviluppa il linguaggio Lisp per studiare la computabilità di funzioni ricorsive su espressioni simboliche che per lungo tempo è stato il linguaggio di riferimento nei progetti di intelligenza artificiale (è stato il primo linguaggio ad adottare i concetti di virtual machine e virtual memory management).
- Sempre McCarthy descrive un programma ideale, Advice Taker, progettato per trovare soluzioni a problemi di tipo non strettamente matematico.
L’adolescenza dell’AI
L’entusiasmo si scontra con le prime difficoltà nella seconda metà degli anni ’60 in quello che in questa nostra metafora è il periodo dell’adolescenza che, come si sa, è sempre accompagnata da grandi quesiti e da problemi che appaiono irrisolvibili. La messa in pratica dei modelli matematici, in teoria funzionanti, si rivela fallimentare per vari motivi.
- Alle macchine manca la conoscenza semantica dei domini trattati. Ci sia consentita una piccola digressione. La memoria è un magazzino nel quale sono custodite tutte le nostre esperienze di vita e tutti sappiamo che esiste quella a breve termine (dove la traccia mnesica, ossia l’immagine mentale, staziona per poco tempo) e a lungo termine (dove l’informazione rimane più a lungo). All’interno di quest’ultima gli studi dell’ultimo secolo distinguono tra memoria episodica e memoria semantica: la prima immagazzina informazioni relative a situazioni che avvengono in un determinato arco di tempo (per esempio: a scuola ho imparato che l’uomo è un mammifero); la seconda è molto più articolata, è composta da significati, simboli e relazioni che si creano tra loro, in pratica rappresenta il patrimonio di conoscenza generale sul mondo di un soggetto (per esempio: so che l’uomo è un mammifero). La memoria episodica e quella semantica non sono localizzate nella stessa area del cervello per cui non sono soggette a processo degenerativo nello stesso momento (posso dimenticare che ho imparato a scuola che l’uomo è un mammifero ma continuo a sapere che lo è). Sebbene affascinante, non approfondiamo ulteriormente questo tema ma un accenno era fondamentale perché ci permette di capire che il motivo per cui la messa in pratica dei modelli matematici ideati negli anni precedenti si traduce, nella pratica, in fallimenti: ci si rende conto che la capacità di ragionamento delle macchine si basa solo su una mera manipolazione sintattica (ossia sviluppare relazioni e correlazioni sulla base di regole e singoli episodi) e non è in grado di sviluppare e correlare significati (conoscenza semantica).
- Nel 1969 i matematici Marvin Minsky e Seymour Papert mettono in discussione il percettrone di Rosenblatt dimostrando che, nonostante questo fosse in grado di apprendere qualsiasi funzione potesse rappresentare, un percettrone con due input non era in grado di rappresentare una funzione che riconoscesse quando i due input sono diversi. Nel mondo scientifico si diffonde la sfiducia nelle reti neurali e bisognerà attendere 20 anni prima che tornino alla ribalta grazie agli studi di Jay McClelland e David Rumelhart.
L’intelligenza artificiale oggi: stato dell’arte e tecnologie a supporto
Quello che stiamo vivendo, a partire dagli anni ’80, è un periodo di grande fermento sui temi dell’intelligenza artificiale e possiamo paragonarlo a quello di un essere umano nel pieno della propria giovinezza, ricco di energie e voglia di sperimentare, ma anche con l’adeguata capacità di analizzare quanto appreso, valutarne potenzialità e possibili sviluppi. E si chiude qui la nostra metafora perché, il passo successivo, quello della maturità, è ancora all’orizzonte. Ma ecco, gli snodi chiave di questi ultimi 40 anni suddivisi per filoni.
Reti neurali
Analizzeremo nel dettaglio questo tema più avanti, quando parleremo di deep learning, ma diamo qui alcune nozioni storiche di base.
Abbiamo visto nel paragrafo precedente che la prima teorizzazione delle reti neurali artificiali (il percettrone di Rosenblatt) era stata messa in discussione, ma nel 1986, Jay McClelland e David Rumelhart pubblicano Parallel distributed processing: Explorations in the microstructure of cognition gettando le basi del connessionismo e dando nuovo vigore agli studi in questo campo: una rete neurale è un grafo diretto non lineare, nel quale ogni elemento di elaborazione (ogni nodo della rete) riceve segnali da altri nodi ed emette a sua volta un segnale verso altri nodi. In pratica, mentre in un computer la conoscenza è concentrata in un luogo ben preciso, la memoria, nella rete neurale la conoscenza non è localizzabile, è distribuita nelle connessioni della rete stessa consentendo alla rete di imparare dalle proprie esperienze.
Si sviluppa il modello di rete neurale multistrato (MLP-Multilayer Perceptron) dove ogni strato di nodi è completamente connesso con quello successivo e utilizza una tecnica di apprendimento supervisionato chiamata retropropagazione dell’errore (che spiegheremo più avanti nel capitolo del deep learning) per l’allenamento della rete che parte da un risultato già noto per un campione specifico.
Nanotecnologie
L’evoluzione delle nanotecnologie, ossia la miniaturizzazione sempre più spinta di microprocessori, ha portato allo sviluppo di una nuova generazione di componenti (dalle General Purpose GPU alle ResistiveRAM ai chip antropomorfici) che hanno dato nuovo impulso all’intelligenza artificiale grazie alla enorme potenza di calcolo messa a disposizione. Li vedremo nel dettaglio più avanti, nel capitolo Le tecnologie che abilitano e supportano l’intelligenza artificiale.
Algoritmi innovativi
Se i filoni precedenti rappresentano (con un ultimo parallelismo con la nostra metafora) la fisicità dell’intelligenza artificiale, gli algoritmi dovrebbero rappresentare ciò che più si avvicina al pensiero: quella “magica” azione che rende l’uomo un essere del tutto speciale rispetto agli altri animali. È proprio dall’evoluzione di metodologie e algoritmi innovativi che trae linfa vitale l’intelligenza artificiale ed è su questi che ci focalizzeremo nelle parti di questo articolo dedicate a machine learning, deep learning, natural language processing e realtà aumentata e realtà virtuale.
Cognitive computing
Utilizzando algoritmi di autoapprendimento, data mining e big data analytics, riconoscimento di pattern, elaborazione del linguaggio naturale, signal processing (un segnale è una variazione temporale dello stato fisico di un sistema o di una grandezza fisica che serve per rappresentare e trasmettere messaggi ovvero informazione a distanza, quindi l’analisi dei segnali è una componente che supporta il cognitive computing) e implementando le più avanzate tecnologie hardware vengono realizzate piattaforme tecnologiche che cercano di imitare il cervello umano, partendo da attività più semplici per arrivare a elaborazioni sempre più complesse. Dallo storico IBM Watson, il primo supercomputer commerciale di questo tipo, a Google Deepmind fino a Baidu Minwa sono ormai diversi gli esempi oggi disponibili (con modelli anche molto diversi tra loro, come vedremo più avanti).
Intelligenza artificiale o intelligenza aumentata? AI debole o AI forte?
Intelligenza artificiale o intelligenza aumentata? Può apparire strano, dopo aver parlato fino ad ora di intelligenza artificiale, porsi questa domanda, ma non è una domanda peregrina.
Come vedremo nella parte dedicata ai temi etici, l’intelligenza artificiale se da un lato apre grandi opportunità, dall’altro alza anche il sipario su scenari, per ora solo fantascientifici, ma sicuramente allarmanti di un mondo governato dalle macchine.
In realtà, come si vedrà quando riporteremo alcuni esempi applicativi, il massimo livello raggiunto finora è quello di un ottimo studente, con una memoria poderosa, ma non del genio. Le macchine fino ad ora correlano ciò che hanno imparato, da questi insegnamenti traggono nuove informazioni per simulare il comportamento umano, ma non hanno le illuminazioni geniali di un Einstein e soprattutto non sviluppano proprie capacità cognitive, ma emulano quelle umane. Sicuramente però possono supportare l’uomo mettendogli a disposizione correlazioni che una mente umana difficilmente potrebbe fare, macinando la quantità infinita di dati oggi disponibili e contribuendo quindi ad “aumentare” l’intelligenza umana; per questo in alcuni contesti si preferisce utilizzare il termine “intelligenza aumentata” invece di “intelligenza artificiale”
Questo dibattito rispecchia quello che, all’interno della comunità scientifica, si sostanzia nella differenza tra intelligenza artificiale debole (weak AI) e intelligenza artificiale forte (strong AI).
È al filosofo statunitense, nonché studioso del linguaggio, John Searle che dobbiamo l’esplicitazione di questa differenziazione che per la prima volta utilizza il termine “intelligenza artificiale forte” (dalla quale, secondo lo stesso Searle, siamo ancora lontani) nell’articolo Menti, cervelli e programmi pubblicato nel 1980. Non è questa la sede per approfondire l’intenso dibattito che si sviluppa intorno a questa tematica, ma ci limitiamo a riportare sinteticamente le due definizioni.
Intelligenza artificiale debole
Agisce e pensa come se avesse un cervello, ma non è intelligente, simula solo di esserlo: per fornire la risposta a un problema indaga su casi simili, li confronta, elabora una serie di soluzioni e poi sceglie quella più razionale e, sulla base dei dati analizzati, più coerente simulando il comportamento umano. L’AI debole non comprende totalmente i processi cognitivi umani, ma si occupa sostanzialmente di problem solving (risposte a problemi sulla base di regole conosciute).
Intelligenza artificiale forte
Ha capacità cognitive non distinguibili da quelle umane. Si collocano in questo ambito i “sistemi esperti” cioè software che riproducono prestazioni e conoscenze di persone esperte in un determinato ambito. Il cuore di questi sistemi è il motore inferenziale ossia un algoritmo che, come la mente umana, da una proposizione assunta come vera passa a una seconda proposizione, con logiche di tipo deduttivo (quando da un principio di carattere generale ne estrae uno o più di carattere particolare) o induttivo (quando avviene il contrario), la cui verità è derivata dal contenuto della prima. La caratteristica distintiva di questi sistemi è l’analisi del linguaggio per comprenderne il significato perché senza comprensione del significato (ricordate quello che abbiamo scritto, descrivendo il momento dell’adolescenza dell’AI, sulla memoria semantica?) non c’è vera intelligenza.
Vediamo quali sono metodologie, tecniche e algoritmi che oggi contribuiscono a popolare il mondo dell’intelligenza artificiale.
Machine learning: tecniche e metodologie algoritmiche
La madre di tutti gli algoritmi di intelligenza artificiale è il machine learning ossia l’apprendimento automatico: la capacità di imparare ed eseguire compiti da parte della macchina sulla base di algoritmi che imparano dai dati in modo iterativo. Non si tratta di una disciplina recente: alcuni algoritmi di machine learning sono diffusi da anni, ma quello che è cambiato oggi è la grande massa di dati sui quali poter applicare calcoli matematici complessi e dato che l’aspetto più importante del machine learning è la ripetitività, più i modelli sono esposti ai dati, più sono in grado di adattarsi in modo autonomo.
Vi sono diverse tecniche di machine learning:
- apprendimento supervisionato: vengono forniti all’algoritmo dati associati a un’informazione che ci interessa e, sulla base di questi dati, l’algoritmo impara a capire come comportarsi; in pratica, il compito dell’algoritmo è quello di mettere in relazione dati conosciuti definendo un modello sulla base del quale dare un risultato corretto al presentarsi di un evento non presente nella casistica precedente. Un esempio classico è la classificazione dei clienti potenziali sulla base del profilo e della storia di acquisto di altri clienti.
- apprendimento non supervisionato: in questo caso non vengono utilizzati dati classificati in precedenza. L’algoritmo deve essere in grado di derivare una regola per raggruppare i casi che si presentano derivando le caratteristiche dai dati stessi. Come si può facilmente immaginare, siamo in presenza di una metodologia molto più complicata della precedente, dove l’algoritmo è molto più complesso poiché si tratta di estrarre dai dati informazioni non ancora note. Viene utilizzato per la definizione di raggruppamenti omogeni di casi: in ambito medico, per esempio, questa metodologia può essere utilizzata per definire una nuova patologia sulla base di dati che fino a quel momento non erano stati messi in relazione. È la metodologia che si è potuta sviluppare con maggiore efficacia grazie alla crescita dei big data.
- apprendimento per rinforzo: L’algoritmo conosce l’obiettivo da raggiungere (per esempio vincere una partita a scacchi) e definisce il modo in cui comportarsi sulla base di una situazione (la configurazione della scacchiera) che cambia (in seguito alle mosse dell’avversario). Il processo di apprendimento avanza per “premi”, definiti rinforzo appunto (le mosse valide). L’apprendimento è continuo e, proprio come per i giocatori umani, più la macchina “gioca” e più diventa brava. È famoso il duello Deep Blue-Kasparov: espressamente progettato da IBM per giocare a scacchi, Deep Blue perse il primo torneo disputato con il campione di scacchi nella “partita 1” del febbraio 1996 ma ebbe la meglio su Kasparov nella “partita 6” giocata un anno dopo (dopo avere perso altri 2 incontri e averne pareggiati 2).
Queste tecniche si sostanziano con l’applicazione di diverse tipologie di algoritmi. Di seguito riportiamo alcune delle tecniche e metodologie algoritmiche più importanti e utilizzate nel machine learning:
- alberi di decisione: utilizzati in particolar modo nei processi di apprendimento induttivo basati sull’osservazione dell’ambiente circostante da cui derivano le variabili di input (attributi). Il processo decisionale è rappresentato da un albero logico rovesciato dove ogni nodo è una funzione condizionale (figura 1); il processo è una sequenza di test che inizia dal nodo radice e procede verso il basso scegliendo una direzione piuttosto di un’altra sulla base dei valori rilevati. La decisione finale si trova nei nodi foglia terminali. Tra i vantaggi vi è la semplicità e la possibilità, per l’uomo, di verificare attraverso quale processo la macchina è giunta alla decisione. Lo svantaggio è che si tratta di una tecnica poco adatta a problemi complessi.

- classificatori bayesiani: si basa sull’applicazione del teorema di Bayes (dal nome del matematico britannico che, nel XVIII secolo, ha sviluppato un nuovo approccio alla statistica) che viene impiegato per calcolare la probabilità di una causa che ha scatenato l’evento verificato (figura 2). Per esempio: appurato che l’elevata presenza di colesterolo nel sangue può essere causa di trombosi, rilevato un determinato valore di colesterolo, qual è la probabilità che il paziente sia colpito da trombosi? I classificatori bayesani hanno differenti gradi di complessità.

- macchine a vettori di supporto (SVM, dall’inglese Support Vector Machines): sono metodologie di apprendimento supervisionato per la regressione e la classificazione di pattern e appartengono alla famiglia dei classificatori a massimo margine (classificatori lineari che contemporaneamente al tempo minimizzano l’errore empirico di classificazione e massimizzano il margine geometrico, ossia la distanza tra un certo punto x e l’iperpiano che, a sua volta, è un sottospazio lineare di dimensione inferiore di uno (n − 1) rispetto allo spazio in cui è contenuto (n)). In queste macchine, gli algoritmi di learning sono disaccoppiati dal dominio di applicazione che viene codificato esclusivamente nella progettazione della funzione kernel; questa funzione mappa i dati sulla base di caratteristiche multidimensionali e consente di creare un modello approssimativo del mondo reale (3D) partendo da dati bidimensionali (2D). L’applicazione più comune delle SVM è la visione artificiale: nell’immagine di un gruppo dove sono presenti uomini e donne (sulla base della funzione kernel che definisce il sesso considerando vari parametri) la SVM riesce a separare gli uni dalle altre. Un’altra cosa che è importante sapere, nella logica di questo articolo che intende fornire solo alcune indicazioni di base, è che questi classificatori vengono contrapposti alle tecniche classiche di addestramento delle reti neurali artificiali.
- apprendimento ensamble: è la combinazione di diversi metodi (a partire dai classificatori bayesani) per ottenere una migliore prestazione predittiva di quanto non facciano i singoli metodi che combina. Sulla base del “peso” che viene dato ai vari metodi, l’apprendimento ensamble si divide in 3 tecniche fondamentali (bagging, boosting e stacking).
- analisi delle componenti principali (in inglese PCA – Principal Component Analysis): è una tecnica di semplificazione dei dati il cui scopo è quello di ridurre il numero più o meno elevato di variabili che descrivono un insieme di dati ad un numero minore di variabili latenti, limitando il più possibile la perdita di informazioni.
Deep learning: cos’è e come funziona
Entriamo nel campo dell’”apprendimento profondo”, deep learning appunto, che si basa sostanzialmente sulle reti neurali artificiali. Per seguire un filo logico è necessario ripetere alcuni concetti già espressi poco sopra.
- Prima di tutto bisogna ricordare cos’è un neurone umano: è una cellula che raccoglie e instrada gli impulsi nervosi; nel sistema nervoso umano ce ne sono più di 100.000 e hanno un ruolo vitale perché senza ricezione e trasmissione di segnale non c’è vita. Quindi il primo step è stato quello compiuto da McCulloch e Pitts nel 1943 assimilando il comportamento del neurone umano al calcolo binario (presenza/assenza di segnale).
- Il secondo passo è stato quello compiuto da Rosenblatt con il suo percettrone che introduce il primo schema di rete neurale artificiale basata su uno strato di ingresso e uno di uscita, nel mezzo una regola di apprendimento intermedia. Come abbiamo visto, l’applicazione di questo modello matematico si dimostra però incapace di risolvere problemi complessi.
- Un passo decisivo viene compiuto da Rumelhart con l’introduzione del terzo strato delle reti neurali (quello che viene chiamato hidden, nascosto) aprendo la strada alle reti MLP – Multi-Layers Perceptron. È nei livelli “nascosti” che avviene la “magia” e la rete neurale artificiale si avvicina al sistema nervoso umano: nei livelli nascosti ogni neurone di un livello è collegato a tutti i neuroni del livello immediatamente precedente e a tutti quelli del livello immediatamente successivo; ogni collegamento ha un “peso” (un valore numerico) che misura quanto è importante il collegamento fra due particolari neuroni (figura 3).
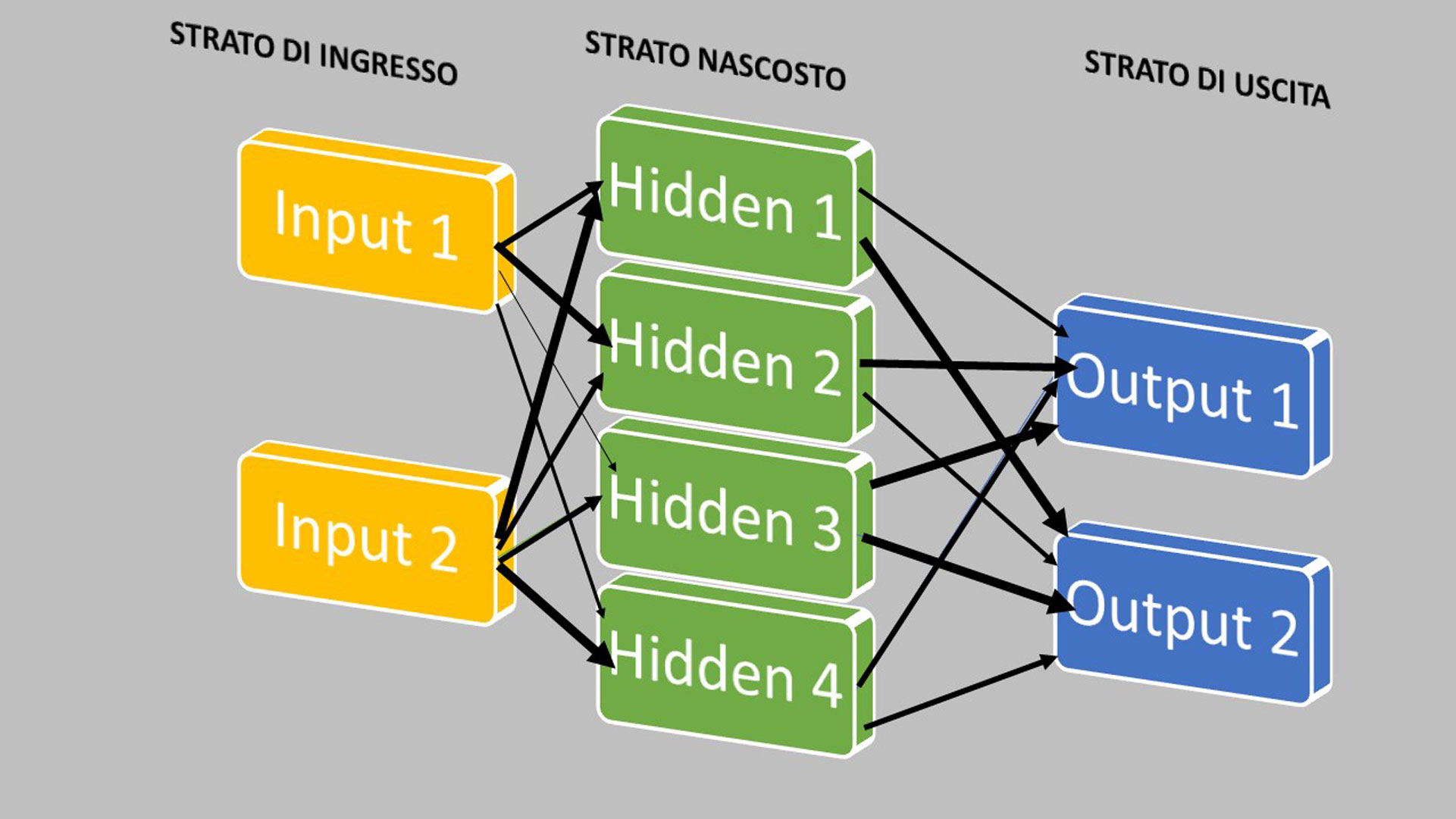
Dal punto di vista concettuale, questo è il punto a cui siamo arrivati oggi e le evoluzioni sono per il momento circoscritte all’invenzione di algoritmi sempre più sofisticati che si basano su questo concetto. Non che sia una cosa semplice, intendiamoci, anche perché la vera potenza dell’algoritmo è data dalla capacità di allenare la rete neurale, di farle acquisire esperienza. Come? Spieghiamolo in 3 step:
- Fase di apprendimento. Solitamente si utilizza la back propagation: si inserisce nella rete un input relativo a un esercizio del quale la rete conosce l’esito corretto, lo si fa arrivare alla fine facendolo passare per tutti gli strati nascosti; dato che la rete è “ignorante”, il passaggio da uno strato all’altro avviene in modo casuale e l’output sarà quasi sicuramente sbagliato; sapendo però quale avrebbe dovuto essere la risposta corretta, la rete capisce di quanto ha sbagliato e torna indietro nel percorso impostando man mano parametri diversi che, ad ogni livello, si avvicinano sempre più al percorso corretto. Più sono gli esempi (e migliori sono) che vengono “digeriti” dalla rete e propagati all’indietro e maggiore sarà la probabilità che la rete effettui le associazioni giuste per arrivare alla risposta corretta.
- Fase di test. Quando il programmatore ritiene che la rete sia sufficientemente istruita immette nella rete degli input relativi a problemi dei quali lui (ma non la rete) conosce la soluzione. Questo gli consente di capire se la rete è pronta per poter elaborare problemi veri su dati nuovi oppure se sbaglia ancora troppo spesso e deve quindi essere maggiormente istruita. Se vi siete fatti l’idea che tutto ciò sia relativamente semplice, siete fuori strada: sono necessarie milioni di sessioni di training e di testing per mettere in produzione una rete neurale efficace.
- Messa in produzione. Superata la fase di test, il lavoro non termina con la messa in produzione della rete. Bisogna infatti creare meccanismi di feedback perché non è detto che una rete che funziona bene oggi funzioni bene anche domani: cambiano i contesti, i comportamenti, gli scenari e la rete deve essere in grado di aggiornarsi in tempo quasi reale; per farlo ha bisogno di meccanismi che le facciano capire se sta andando nella direzione giusta o no.
Una frontiera importante per l’evoluzione delle reti neurali, in termini di capacità di elaborazione, è rappresentata dalla ricerca nell’ambito delle nanotecnologie e in particolare dei chip neuromorfici, ma qui si apre un altro capitolo che tratteremo più avanti.
Natural language processing: a cosa serve
Obiettivo del Natural Language Processing (NLP) è quello di dotare i sistemi informatici di conoscenze linguistiche per perseguire 3 scopi principali:
- Assistere l’uomo in attività connesse con il linguaggio: traduzione, gestione di documenti ecc.
- Interagire con gli esseri umani in modo naturale.
- Estrarre automaticamente informazioni da testi o da altri media.
L’enorme difficoltà al trattamento automatico di informazioni scritte o parlate in una lingua naturale è dovuta alla naturale ambiguità e complessità del linguaggio umano: anche se inseriamo in un computer tutte le regole grammaticali, sintattiche e lessicali di una specifica lingua e tutti i vocaboli esistenti, il risultato non sarà un linguaggio naturale perché manca l’assegnazione del significato alle parole e il significato varia in base al contesto, all’esperienza, alla storia stessa della lingua.
Gli studi sul NLP iniziano nel secondo dopoguerra negli USA, ma dopo una ventina d’anni, nel 1966, l’ ALPAC (Automatic Language Processing Advisory Committee) pubblicò un rapporto che sottolineava gli scarsi risultati raggiunti ed evidenziava come la traduzione automatica fosse molto costosa e molto meno accurata di quella umana. Le conoscenze allora disponibili non permettevano di creare algoritmi sufficientemente performanti per supportare il trattamento automatico del linguaggio ed è solo a partire dagli anni ’80 che la ricerca in questo ambito è ripresa grazie all’evoluzione vista nelle tecniche di machine learning, ed è esplosa, con risultati sorprendenti, negli ultimi anni con l’applicazione delle reti neurali che ha consentito di dare una svolta anche al riconoscimento vocale.
Realtà aumentata e realtà virtuale
Anche in questo caso partiamo dalla semplice definizione:
- la realtà aumentata rappresenta la realtà arricchendola con oggetti virtuali grazie all’utilizzo di sensori e algoritmi che consentono di sovrapporre immagini 3D generate dal computer al mondo reale (come avveniva in Pokemon Go, il gioco che per qualche settimana ha fatto impazzire mezzo mondo: il gioco installato sullo smartphone utilizza la fotocamera, il sensore GPS e l’accelerometro per avvisare il giocatore sulla “presenza” di Pokemon da catturare visualizzando attraverso il cellulare un mondo digitale completamente sovrapposto al mondo reale);
- la realtà virtuale, invece, simula completamente un ambiente: nel caso di realtà virtuale immersiva l’utente “entra” all’interno di questo ambiente grazie a speciali visori, guanti dotati di sensori utilizzati per i movimenti, per impartire comandi o tute (sempre dotate di sensori) che avvolgono l’intero corpo; nella realtà virtuale non immersiva l’utente si troverà semplicemente dinanzi ad un monitor, il quale fungerà da finestra sul mondo tridimensionale con cui l’utente potrà interagire attraverso joystick appositi.
Come vedremo più avanti, l’utilizzo a fini ludici di queste tecnologie non è il principale scopo e ormai molte aziende le utilizzano nello sviluppo e nel testing di nuovi prodotti o nella vendita di prodotti e servizi.
Le tecnologie che abilitano e supportano l’intelligenza artificiale
Dal quantum computing, ai chip neuromorfici, alle ReRAM a…. la ricerca per sviluppare tecnologie hardware in grado di supportare gli sviluppi in ambito software (la “croce” dell’informatica da quando è nata) dell’intelligenza artificiale è intensa. Riportiamo qui le tecnologie che attualmente sono disponibili, o in avanzata fase di rilascio, e che possono consentire di realizzare pienamente le promesse di questa disciplina.
General Purpose GPU
Nate nel mondo dei videogiochi per elaborare le informazioni grafiche dei computer, le GPU (Graphic Processing Unit) hanno via via aumentato le proprie prestazioni, soprattutto dopo l’introduzione della grafica 3D nei videogiochi. Per una volta, però, la solita storia dell’informatica si ribalta: contrariamente a situazioni dove il software “divoratore” di capacità computazionale deve “combattere” con l’hardware mai completamente all’altezza, il potenziale di calcolo delle GPU rimaneva inespresso. Parte da questa considerazione la decisione, nel 2007, di Nvidia (uno dei maggiori produttori di acceleratori grafici) di introdurre General Purpose GPU.
Una brevissima digressione per capire come funzionano CPU e GPU: nelle CPU le istruzioni vengono eseguite in maniera seriale sequenziale e tutti i core (i nuclei elaborativi) del processore si occupano della stessa istruzione finché non è terminata; la logica con cui lavora una GPU è invece parallela: molteplici istruzioni vengono eseguite contemporaneamente; per farlo, invece di pochi core ottimizzati per il calcolo seriale, è strutturata con migliaia di unità di elaborazione, meno potenti di quelle delle CPU, ma ottimizzate per lavorare in parallelo.
Le GPGPU possono quindi eseguire porzioni di codice o programmi differenti in parallelo trovando applicazione in campo scientifico, per esempio, dove diversi problemi possono essere scomposti e analizzati parallelamente; velocizzano enormemente, per esempio, le operazioni nelle quali sono richiesti elaborazione e trattamento delle immagini (figura 4).

Tensor Processing Unit
Le Tensor Processing Unit (TPU) sono ASIC (Application specific integrated circuit) progettati e realizzati da Google espressamente per operazioni caratterizzate da alto carico di lavoro, quindi tipicamente quelle di machine learning. Questi circuiti sono destinati a ridurre il tempo dedicato alla fase inferenziale del machine learning (ossia quella che compara i singoli dati con il modello creato nella fase di apprendimento e che costituisce quella con il più elevato carico di lavoro), per questo vengono definiti “acceleratori di AI”: lo sviluppo di questi chip è iniziato nel 2008 e durante il Google I/O 2018, la conferenza annuale dedicata agli sviluppatori web, l’azienda di Mountain View ha presentato la release 3.0 delle TPU che, ha dichiarato l’amministratore delegato di Google Sundar Pichai, ha prestazioni 8 volte superiori rispetto alla v. 2.0, raggiungendo sino a 100 Petaflop per le operazioni di machine learning. Una potenza che, per la prima volta, ha richiesto l’inclusione nel circuito di un sistema di raffreddamento a liquido dato l’elevato calore prodotto.
ReRAM – Resistive Random Access Memory
Le memorie resistive ad accesso casuale sono in grado di immagazzinare dati per 1 terabyte (1.000 gigabyte) in chip grandi come un francobollo, sono non volatili (capaci di mantenere l’informazione salvata anche in assenza di alimentazione elettrica), non hanno bisogno di essere “avviate” e consumano pochissimo. Sono un grande abilitatore tecnologico per le applicazioni di intelligenza artificiale perché componente ideale per la costruzione di reti neurali.
Le memorie resistive trovano fondamento nel cosiddetto memristore (parola formata dalla fusione dei termini memoria e resistore), descritto come il quarto elemento fondamentale di un circuito elettrico (dopo condensatore, induttore e resistore), la cui esistenza sinora era solamente teorica (la teorizzazione compare per la prima volta in un articolo di Leon Chua dell’Università di Berkeley nel 1971).
Nel 2007 negli HP Lab è stata prodotta una versione sperimentale di un dispositivo con caratteristiche simili a quelle di un memristore (quello teorizzato da Chua si basa sulla variazione del flusso elettromagnetico, mentre in questo caso il principio fisico è differente; si tratta però di una questione dibattuta nella quale non ci addentriamo); da allora i principali produttori di microprocessori e memorie hanno lavorato in questa direzione e da un paio di anni varie aziende ne hanno annunciato la produzione (Fujitsu Semiconductor, Western Digital, 4DS Memory, Weebit Nano, Crossbar, Intele altri)
Proprietà fondamentale del memristore è quella di “ricordare” lo stato elettronico a prescindere dall’esistenza di una costante tensione elettrica (motivo per cui non necessita di “riavvio” all’accensione della macchina che lo integra) e di rappresentarlo con stati analogici. Un esempio di vantaggio? La non necessità di caricare il sistema operativo ogni volta che si accende il device: la macchina sarebbe subito “sveglia” appena messa in azione. Le ReRAM hanno una struttura fisica semplice e compatta e le loro caratteristiche le rendono ideali per dispositivi come smartphone o tablet e, in genere, in quelli dell’IoT dato che, oltre a essere 20 volte più veloci delle attuali memorie utilizzate nei dispositivi mobili di ultima generazione, consumerebbero anche 20 volte di meno. Bisogna dire che la ricerca in questo campo è una delle più attive. Nel gennaio 2017, per esempio, la Nanyang Technological University di Singapore, insieme alle tedesche RWTH Aachen University e Forschungszentrum Juelich Research Center hanno annunciato lo sviluppo di un prototipo che, sfruttando le potenzialità dei chip ReRAM, è in grado di svolgere sia le funzionalità di processore sia quelle di RAM. La peculiarità di questo chip, oltre ad essere ancora più veloce e consumare meno dei microprocessori di ultima generazione, è però un’altra: il memristore conserva e processa le informazioni in modalità analogica e non digitale mentre il prototipo euroasiatico adotta quella che viene chiamata computazione ternaria dove ai consueti 0 e 1 del sistema binario si affianca il 2 (combinando i vantaggi del sistema binario con quelli di un sistema che, aggiungendo una dimensione, si avvicina a quello analogico).
Quantum computing
La definizione da vocabolario (Treccani) di computer quantistico è: “Macchina che elabora l’informazione e compie operazioni logiche in base alle leggi della meccanica quantistica. Esso opera cioè secondo una logica quantistica, profondamente diversa da quella classica in base alla quale funzionano gli attuali calcolatori. L’unità di informazione quantistica è il qubit”.
Diciamo che, per chi è a digiuno dei principi di base della fisica moderna, questa definizione non chiarisce molto e quindi riportiamo, per punti, gli step fondamentali che hanno consentito di arrivare a questa tecnologia (tralasciando quelli intermedi strettamente connessi all’evoluzione del concetto in fisica):
- alla fine del XIX secolo, la meccanica classica appariva incapace di descrivere il comportamento della materia o della radiazione elettromagnetica a livello microscopico (scale di grandezza inferiori o uguali a un atomo);
- agli inizi del ‘900, il fisico tedesco Max Planck introduce il concetto di “quanto”: alcune quantità o grandezze di certi sistemi fisici (come l’energia) a livello microscopico possono variare soltanto di valori discreti, detti quanti, e non continui. Il quanto (che deriva dal latino quantum, quantità) è quindi la quantità elementare discreta e indivisibile di una certa grandezza;
- con gli studi degli anni successivi si arriva al concetto di meccanica quantistica che si basa su 5 postulati (che qui non approfondiamo perché ci farebbe deviare dal nostro percorso), ma i fenomeni che si riveleranno particolarmente importanti per lo sviluppo della tecnologia di cui stiamo parlando sono quelli della sovrapposizione degli effetti e della correlazione quantistica (detta entanglement) in base ai quali in determinate condizioni lo stato quantico di un sistema fisico non può essere descritto singolarmente, ma solo come sovrapposizione di più sistemi (o strati);
- la meccanica quantistica rappresenta, insieme alla teoria della relatività, un punto di svolta della fisica classica e apre le porte alla fisica moderna;
- veniamo alla relazione tra meccanica quantistica e informatica: per decenni l’aumento della potenza dei computer è stato regolato dalla cosiddetta Legge di Moore (la densità dei transistor su un microchip e la relativa velocità di calcolo raddoppiano ogni 18 mesi), ma la miniaturizzazione dei componenti presenta oggettivi limiti (oltre i quali non è possibile ridurre le dimensioni dei componenti);
- agli inizi degli anni ’80 del secolo scorso, grazie all’elaborazione di diversi scienziati, si arriva a teorizzare un possibile uso della teoria dei quanti in informatica: al posto dei convenzionali bit (che definiscono 1 dimensione con due stati: aperto/chiuso) si utilizza come unità di misura il qubit (o qbit): la più piccola porzione in cui una qualsiasi informazione codificata può essere scomposta che, per sua natura, è continua. È un concetto che non è facile da comprendere, ma su Wikipedia si trova una metafora che può aiutare per comprendere la natura “continua” del qbit: “Mentre il bit classico è immaginabile come una moneta che, una volta lanciata, cadrà a terra mostrando inesorabilmente una delle due facce, il qbit è immaginabile come una moneta che, una volta lanciata, cadrà a terra continuando a ruotare su sé stessa senza arrestarsi finché qualcuno non ne blocchi la rotazione, obbligandola a mostrare una delle sue facce”. Insieme alla natura continua, l’altro fenomeno della meccanica quantistica che è importante ai fini della tecnologia dei computer quantistici è quello dell’entanglement in base al quale, nel momento in cui vengono combinati, due qbit perdono la loro natura individuale per assumerne una unica di coppia e quindi lo stato di un qbit influenza quello dell’altro e viceversa portando a una combinazione matematica esponenziale.
- facciamo ora un salto agli anni più recenti per riportare gli sviluppi più recenti di questa tecnologia: nel maggio 2011 la canadese D-Wave Systems annuncia il computer quantistico D-Wave One (che però ha sollevato dubbi in parte della comunità scientifica sull’effettivo utilizzo di qbit nei suoi processori) e nel 2013 viene annunciata la collaborazione con Nasa e Google per lo sviluppo di computer quantici per il machine learning;
- nel 2016 IBM annuncia la disponibilità per i propri clienti, attraverso il servizio cloud IBM Quantum Experience, di un processore quantistico a 5 qbit che si trova presso il Watson Research Center di IBM a New York, mentre nei suoi laboratori si lavora alla realizzazione di un processore a 50 qubit;
- nel 2017 Intel annuncia la consegna del suo primo chip quantistico con 17 qbit al partner olandese QuTech;
- nel marzo 2018 Google Quantum AI Lab ha annunciato la creazione di Bristlecone, un processore quantistico dotato di 72 qbit
Chip neuromorfici
Si tratta di chip in grado di simulare il funzionamento del cervello umano quindi, come abbiamo visto per le reti neurali, basati su una logica di funzionamento non binaria bensì analogica: si attivano in maniera differente a seconda del gradiente di segnale (o peso, vi ricordate la dimensione delle linee che collegano gli elementi delle reti neurali?) scambiato tra due o più unità.
Processori di questo tipo si rivelerebbero fondamentali per lo sviluppo di reti neurali artificiali e negli ultimi anni la ricerca si è molto concentrata, con risultati altalenanti, su questi chip. Riportiamo solo l’annuncio più recente, del gennaio 2018, dei ricercatori del MIT di Boston: fino a oggi nei chip “neuromorfici” la sinapsi (il collegamento) era formata da due strati conduttori separati da un materiale amorfo, in cui le particelle elettricamente cariche usate come messaggeri erano libere di muoversi in modo incontrollabile: in questo modo la performance della sinapsi poteva variare di volta in volta, senza garantire uniformità. I ricercatori del MIT hanno sfruttato del silicio monocristallino al posto del materiale amorfo: all’interno di questo materiale, formato da un reticolo cristallino continuo, è stato creato un ‘imbuto’ che consente il passaggio degli ioni in modo uniforme e controllabile. Le sinapsi artificiali così create sono riuscite a superare un test di apprendimento per il riconoscimento di diversi tipi di calligrafia con un’accuratezza del 95%.
Piattaforme e servizi di intelligenza artificiale: un mercato in crescita
IDC rileva che la spesa aziendale a livello worldwide in sistemi AI, cognitivi e di machine learning raggiungerà i 77,6 miliardi di dollari nel 2022, più di tre volte il valore di mercato previsto per il 2018, vale a dire 24 miliardi.
In Europa Occidentale, gli investimenti da parte delle imprese ammonteranno a 3 miliardi di dollari entro la fine del 2018, con una crescita del 43% rispetto al 2017, e nel 2022 il mercato arriverà a valere 10,8 miliardi di dollari (CAGR +39%); l’Italia risulta essere in linea con questo trend grazie a una spesa aziendale in intelligenza artificiale che nel 2018 si assesterà intorno ai 17 milioni di euro (+31% sul 2017) e nel 2019 arriverà poco sotto ai 25 milioni (+44%).
Per quanto riguarda i settori, sempre relativamente all’Europa Occidentale, IDC segnala che il podio dei maggiori investitori vede oggi al primo posto il bancario, seguito dal retail e dal manufacturing, ma rileva anche che entro il 2022 il retail scalzerà il bancario grazie al grande interesse verso l’automazione del servizio clienti (per esempio implementazione di chatbot e assistenti virtuali). Analizzando la crescita percentuale media annua (CAGR) per settore, IDC segnala che il settore sanitario si distinguerà dalle altre industry per la fortissima crescita.
Le piattaforme e servizi di AI per le aziende: l’approccio dei big
Coming soon – A breve integreremo questo articolo con una parte dedicata alle specifiche piattaforme. Per essere informato quando questa parte verrà aggiornata iscriviti alla Newsletter di ZeroUno.
Gli ambiti di applicazione dell’AI
Coming soon – A breve integreremo questo articolo con una parte dedicata agli ambiti applicativi. Per essere informato quando questa parte verrà aggiornata iscriviti alla Newsletter di ZeroUno.
L’impatto economico dell’AI
Riuscire a quantificare l’impatto di queste tecnologie sul sistema economico e sociale mondiale è un esercizio molto difficile dato che le variabili in campo sono tante, complesse e correlate con temi di difficile previsione (soprattutto a lungo termine). Nell’articolo Quale è oggi e in futuro l’impatto economico dell’intelligenza artificiale?abbiamo analizzato alcuni trend che determineranno l’impatto economico dell’AI sull’economia mondiale. In questo contesto riassumiamo alcuni indicatori che aiutano a misurare questo impatto sulla base di ricerche e survey condotte da varie società di ricerca.
Secondo una survey condotta da IDC a livello mondiale nella prima metà del 2018 (della quale però non è stato fornito il campione coinvolto), l’intelligenza artificiale porterà i maggiori benefici all’IT (per il 58% dei rispondenti, risposte multiple consentite), agli operation team (49%) e allo sviluppo di prodotti (43%); più in generale sull’intera organizzazione aziendale, l’AI migliorerà la produttività della forza lavoro (per il 20% dei rispondenti, risposte singole), genererà innovazione e crescita dei ricavi (18%), velocizzerà i processi decisionali (17%).
Specificatamente rivolta al mondo industriale è stata invece la survey The Present and Future of AI in the Industrial Sector condotta da HPE e Industry of Things World, conferenza europea di riferimento per il mondo dell’Industrial IoT, che ha coinvolto 858 professionisti ed executive di aziende industriali europee. La maggioranza degli intervistati (61%) risulta già impegnata a qualche titolo nella AI: l’11% ha già implementato la tecnologia nelle funzioni o nelle attività di base; il 14% prevede di farlo nei prossimi dodici mesi e il 36% ne sta valutando l’implementazione. La previsione di crescita del fatturato conseguente all’adozione di una qualche forma di intelligenza artificiale è di circa l’11,6% entro il 2030, con un incremento dei margini del 10,4%. Ma una delle cose più interessanti che emerge da questa indagine è che queste previsioni si basano sulle elevate percentuali di successo dei progetti di AI completati (risultato in genere non scontato nell’adozione di tecnologie d’avanguardia): il 95% degli intervistati che hanno già implementato la AI nelle rispettive aziende afferma di aver raggiunto, migliorato o significativamente superato i propri obiettivi. Di conseguenza, il campione intervistato prevede di investire mediamente lo 0,48% del proprio fatturato a favore dell’AI nei prossimi 12 mesi, una somma rilevante considerando come nel comparto industriale il budget IT complessivo medio sia pari all’1,95% del fatturato. In linea con queste prospettive positive, due terzi degli interpellati prevedono che i nuovi posti di lavoro creati dalla AI bilanceranno o addirittura supereranno il numero di quelli resi ridondanti dalla stessa AI.
Qualche mese fa nell’articolo AI: una strategia per cogliere le opportunità di businessabbiamo illustrato nel dettaglio una survey realizzata da MITSloan Management Review in collaborazione con BCG-The Boston Consulting Group realizzata a livello mondiale nella primavera del 2017 presso 3.000 business executive con 30 interviste approfondite ad analisti ed esperti tecnologici, nella quale emergeva che se un anno e mezzo fa solo il 14% riteneva che queste tecnologie potessero avere un impatto sulla propria offerta di prodotti e servizi, ben il 63% pensava che invece avrebbero avuto forti impatti in quest’ambito e il 59% attribuiva un notevole impatto dell’AI sui processi.
Lo studio del McKinsey Global Institute (MGI) che si intitola, appunto, Modeling the Impact of AI on the World Economy afferma che entro il 2030 l’AI potrebbe determinare un aumento dell’attività economica globale di circa 13 trilioni di dollari, con una crescita di circa 1,2% del PIL all’anno; l’impatto, se si dovesse confermare questa previsione, sarebbe simile a quello che hanno avuto nel 1800 il motore a vapore, i robot nella produzione industriale negli anni ’90 o la diffusione dell’IT negli anni 2000. Stiamo quindi parlando di tecnologie che possiamo definire a tutti gli effetti disruptive.
È però importante sottolineare che l’impatto dell’AI molto probabilmente non sarà lineare: emergerà gradualmente e sarà visibile nel tempo con un’accelerazione crescente più ci si avvicina al 2030. L’ipotesi è di un’adozione dell’AI basata sul classico modello della curva a S, con un avvio lento a causa di costi e investimenti sostanziali associati all’apprendimento e all’implementazione di queste tecnologie e un’accelerazione successiva determinata dall’effetto cumulativo e da un miglioramento delle capacità complementari.
Un’ultima considerazione relativa a queste ipotesi di crescita riguarda il modo in cui le aziende e i paesi sceglieranno di abbracciare l’intelligenza artificiale: per le prime, se la scelta è più orientata verso l’utilizzo di queste tecnologie per ottenere una maggiore efficienza oppure maggiormente rivolta allo sviluppo di soluzioni e prodotti innovativi l’impatto sarà differente; così se i paesi avranno un approccio di apertura (sostanziato da provvedimenti legislativi, sostegno economico, incentivi, sviluppo di percorsi formativi adeguati ecc.) o un atteggiamento prudente se non addirittura ostile a queste tecnologie questo non potrà che influire, anche in modo determinante, sui risultati economici ipotizzati.
L’applicazione dell’AI per settori: alcuni esempi
L’intelligenza artificiale non è più una disciplina relegata ai laboratori di ricerca. Sono diffuse le applicazioni e sono diversi gli esempi dove le diverse tecnologie di AI sono implementate. Si tratta di un capitolo che, per sua natura, non può essere esaustivo, ma che cercheremo di aggiornare con regolarità, per cui per essere informato quando questa parte verrà aggiornata iscriviti alla Newsletter di ZeroUno.
Ma prima di illustrare alcuni ambiti, vogliamo ricordare i due elementi che stanno, da un lato, rendendo possibile la diffusione di applicazioni AI in ambito business, e dall’altro, le rendono disponibili in tempo reale là dove servono:
- A rendere possibile l’utilizzo di applicazioni AI su vasta scala in ambito business, a “democratizzarne” l’accesso rendendole fruibili anche a realtà medio piccole e non solo alle grandi corporation, è la diffusione del cloud computing. La fruizione di tecnologie e applicazioni AI dai più diffusi cloud pubblici, nei quali avviene la potente massa elaborativa necessaria per eseguire applicazioni di AI, apre le porte anche a chi non ha grandi possibilità di investimento.
- Il secondo elemento che è fondamentale è l’edge computing: nelle applicazioni dove è necessario avere una risposta immediata a problematiche risolvibili con applicazioni di intelligenza artificiale queste devono essere eseguite là dove il dato viene raccolto, con un’elaborazione periferica (e per questo sono tanto importanti evoluzioni tecnologiche come le ReRAM.
Sanità
In questo ambito, il potenziale di applicazione è ampio, grazie a tutto ciò che si può fare con l’analisi dei big data e della storia clinica dei pazienti applicando il machine learning: dai miglioramenti in fase diagnostica alla possibilità di somministrare cure personalizzate in base al corredo genetico dell’individuo.
Grandi sono anche le promesse dell’intelligenza artificiale per la previsione e prevenzione di malattie o epidemie su larga scala. Le applicazioni per l’e-health sono davvero tante. Si va dal monitoraggio in remoto delle condizioni di salute grazie ai wearable device, all’effettuazione di test di routine senza l’intervento del medico, fino al calcolo delle probabilità che un paziente sia affetto da una malattia, per non parlare del supporto che può fornire agli studi in ambito genetico e sul genoma.
Ne possono trarre vantaggio le strutture ospedaliere, ma anche il sistema sanitario di interi paesi, grazie alla riduzione dei costi di ospedalizzazione. Una indagine di mercato realizzata da Accenture nel 2018 stima che la sanità USA entro il 2026 potrebbe risparmiare 150 miliardi di dollari grazie ad applicazioni di intelligenza artificiale sia in ambiti strettamente legati all’attività medica (dalla medicina generale alla chirurgia, alla somministrazione di farmaci) sia per quanto riguarda la sicurezza informatica in ambito ospedaliero.
Tractica, società specializzata in ricerche di mercato nell’ambito dell’AI e della robotica, nel 2017 stimava che le entrate mondiali delle tecnologie per l’analisi delle immagini mediche dovrebbero raggiungere i 1.600 milioni di dollari entro il 2025, mentre le entrate globali delle app di assistenza virtuale potrebbero, sempre entro la stessa data, superare i 1.200 milioni di dollari.
Di seguito indichiamo alcuni dei più recenti articoli pubblicati da ZeroUno e altre testate del Gruppo Digital360 su AI e sanità.
- Futureland 2018: sul palco blockchain, intelligenza artificiale e tecnologie immersive
- Sistemi cognitivi al centro per la gestione delle malattie professionali in Inail
- Sicurezza informatica in sanità, quali tecnologie e misure adottare?
- Intelligenza artificiale e medicina, accordo tra IBM Watson Health e Guerbert
- Intelligenza artificiale, uno sguardo alla Sanità del futuro
- Nuova collaborazione tra Amgen ed IBM: un assistente virtuale personalizzato al servizio dei nefrologi
- Intelligenza artificiale e medicina: un rapporto sempre più stretto
- Realtà virtuale e psichiatria: il caso della schizofrenia
- Intelligenza artificiale in Sanità: la via per un’applicazione concreta
- La realtà virtuale al servizio della disabilità: parte il Progetto “QuotidianaMente”
- Health-tech, l’intelligenza artificiale migliorerà la salute di cittadini e aziende
- IoT e AI aiutano l’assistenza agli anziani: Casa Sole lo fa con IBM Watson
- HealthTech, Liquidweb raccoglie 2,5 milioni di euro
Automotive
Una delle applicazioni più note dell’intelligenza artificiale nel mondo dell’auto è quella delle auto autonome: secondo il colosso della finanza BlackRock nel 2025 il 98% dei veicoli sarà connesso e nel 2035 il 75% sarà a guida autonoma.
L’applicazione dell’AI nella guida autonoma non manca di sollevare problemi etici. I ricercatori del MIT hanno pubblicato nell’ottobre 2018 su Nature i risultati del sondaggio The Moral Machine experiment che ha coinvolto 2 milioni di persone in 233 paesi per capire cosa pensa la gente riguardo alle scelte che un’auto a guida autonoma dovrebbe compiere in caso di emergenza. Se l’auto deve scegliere se schiantarsi (rischiando di uccidere il guidatore) per non investire un bambino, che deve fare? E se invece del bambino c’è un anziano? E se deve scegliere tra investire un gruppo di persone o una persona sola? O se da una parte c’è un senza tetto e dall’altra una signora ben vestita? Se su alcune risposte (meglio salvare persone che animali, gruppi più numerosi rispetto a gruppi meno numerosi) il parere era abbastanza condiviso su altre sono emerse differenze culturali: in America Latina, per esempio, si preferisce salvare i giovani rispetto agli anziani, mentre per gli asiatici l’auto dovrebbe scegliere di salvare gli anziani rispetto ai giovani.
Ma non occorrerà attendere le auto che guidano da sole per vedere l’AI implementata sulle auto: un esempio sono le videocamere intelligenti dotate di sistemi di facial recognition, già oggi installate su tir e veicoli commerciali: rilevano lo stato del guidatore monitorando stanchezza, distrazioni, stati di scarsa lucidità (consentendo, oltre di evitare incidenti, di abbassare i costi assicurativi per le flotte commerciali) e alcune case automobilistiche stanno sviluppando soluzioni, meno costose, da implementare sulle automobili.
E, in ogni caso, se alcune (per il momento un numero limitato) realtà stanno lavorando intensamente sulle auto a guida completamente autonoma, un numero crescente di produttori sta sviluppando servizi di AI a supporto del guidatore: sistemi per evitare collisioni, alert per la segnalazione di pedoni o ciclisti ecc.
Di seguito indichiamo alcuni dei più recenti articoli pubblicati da ZeroUno e altre testate del Gruppo Digital360 su AI e Automotive
- Smart car, così l’intelligenza artificiale rivoluzionerà il powertrain
- Intelligenza artificiale e auto, il Gruppo PSA apre un Open Lab con un centro di ricerca pubblico
- Intelligenza artificiale, ecco come rivoluzionerà il mondo delle auto
Finance e mercato azionario
Secondo una ricerca condotta da Accenture nell’aprile 2018 (che ha visto il coinvolgimento di 100 CEO e top manager e 1.300 impiegati, a livello mondiale, del settore bancario), il 76% di CXO degli istituti bancari ritiene che l’adozione di tecnologie di AI entro il 2022 sarà un fattore critico di successo in questo mercato. Facciamo solo due esempi: i dati sulle abitudini individuali di rimborso, il numero di prestiti attivi in un dato momento, il numero di carte di credito intestate e altri dati possono essere utilizzati per personalizzare il tasso di interesse su una carta o su un mutuo e, sulla base delle risposte, il sistema di machine learning a supporto di questi servizi può migliorare ulteriormente offrendone di nuovi; lo stesso meccanismo può risultare estremamente efficace nella rilevazione e gestione delle frodi dove il sistema, imparando dai propri errori, può essere sempre più efficace.
La AI sta ridefinendo il tipo di servizi finanziari offerti e la loro modalità di erogazione? Con quale impatto sugli istituti finanziari e quali vantaggi per i clienti? Sono le domande alle quali ha cercato di dare delle risposte il corposo studio dell’agosto 2018 realizzato dal World Economic Forum in collaborazione con Deloitte, The New Physics of Financial Services – Understanding how artificial intellligence is transforming the financial ecosystem, dal quale riprendiamo alcuni spunti.
Lo studio rileva che sono molto numerosi gli specifici servizi finanziari che possono ottenere importanti benefici dall’adozione di tecnologie di intelligenza artificiale. Come si vede nella figura 5, questi servizi sono stati raggruppati in 6 ambiti: Depositi e prestiti, Assicurazione, Pagamenti, Gestione degli investimenti, Capital markets (tutte le attività relative alla gestione degli strumenti finanziari emessi dai clienti della banca come obbligazioni, azioni e derivati) e Market infrastructure (intermediazione di servizio di brokeraggio per esempio gestione derivati). Ogni servizio si posiziona poi su una scala di maturità che parte dall’utilizzo dell’AI per “fare meglio le cose” (A) per arrivare a un utilizzo che consente di “fare le cose in modo radicalmente diverso” (B).
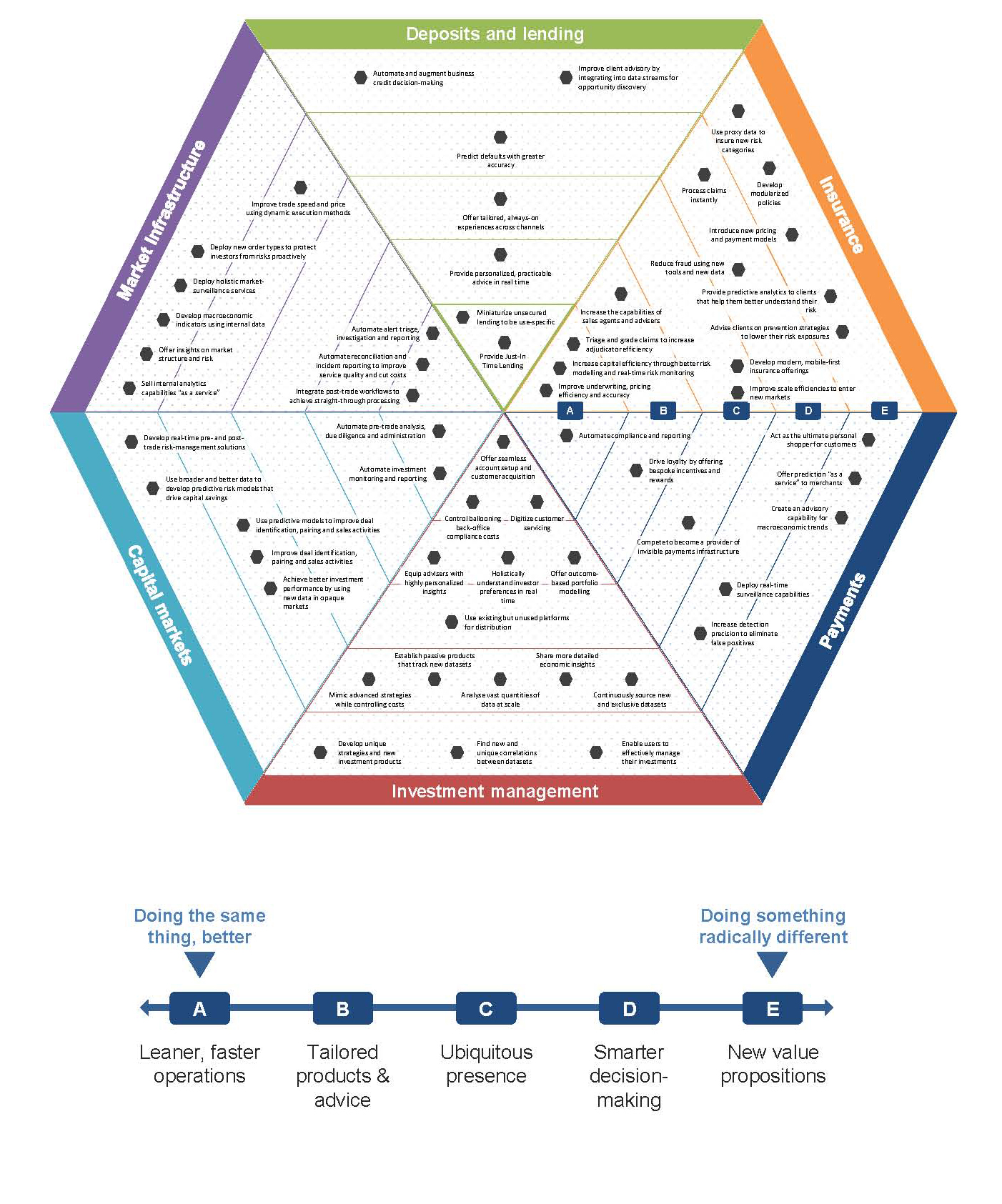
Impossibile riassumere in poche righe il corposo studio di oltre 150 pagine, per cui ci limiteremo a riassumere alcune delle principali evidenze emerse (per ciascuna delle quali, lo studio presenta esempi concreti).
- Trasformare gli investimenti in AI in centri di profitto diretto. I processi di back-office abilitati all’IA possono essere migliorati più rapidamente se vengono offerti as a service ad altre aziende (anche competitor): nella figura 6, che evidenzia le differenze tra un modello tradizionale di implementazione di AI e uno di back office come servizio, si evidenzia come questa seconda opzione, che abilita un miglioramento continuo dei servizi basato su ciò che si apprende nell’eseguirli presso i clienti, induca vantaggi economici diretti per il fornitore dei servizi.

Figura 6 – Differenze tra un modello tradizionale di implementazione di AI e uno di back office come servizio – Fonte: World Economic Forum, The New Physics of Financial Services – Understanding how artificial intellligence is transforming the financial ecosystem - L’AI è un nuovo campo di battaglia sul quale giocarsi la fedeltà del cliente. L’AI abilita nuove strade per differenziare la propria offerta ai clienti basata su una personalizzazione estremamente puntuale dei servizi che possono essere offerti in tempo reale al manifestarsi di un’opportunità di mercato o di un’esigenza del cliente stesso.
- Servizi finanziari auto gestiti. Grazie all’AI, la customer experience può cambiare radicalmente con un’interazione diretta tra il cliente e gli “agenti” di AI dei diversi fornitori di servizi finanziari (o dei diversi servizi dello stesso fornitore) che consente al primo di autogestire, in modo completamente autonomo rispetto alla tradizionale consulenza finanziaria, i propri investimenti. Sempre nella logica del circolo virtuoso visto per il punto 1, inoltre, gli algoritmi di AI, grazie a questa interazione continua, acquisiscono nuovi insegnamenti per migliorare.
- Soluzioni collettive per problemi condivisi. Strumenti di collaborazione basati su AI, che si sviluppano su dataset condivisi, possono rendere più sicuro ed efficiente il sistema finanziario nel suo insieme (figura 7) .

Figura 7 – Maggiore sicurezza del Sistema finanziario grazie all’AI
Fonte: World Economic Forum, The New Physics of Financial Services – Understanding how artificial intellligence is transforming the financial ecosystem - Polarizzazione della struttura del mercato dei servizi finanziari. La diffusione dell’AI porterà a una graduale scomparsa delle realtà di medie dimensioni per andare, da una parte, verso una sempre maggiore concentrazione (processo già in atto da tempo in questo mercato a causa di altri fattori per i quali rimandiamo all’articolo Finance, i fattori esterni e interni che stanno trasformando il settore) perché le economie di scala rendono sempre più efficiente (vedi punti 1 e 3) i servizi basati su queste soluzioni. L’altro polo è composto da una proliferazione di piccolissime realtà, molto agili, in grado di offrire prodotti di nicchia.
- Cambiano le partnership. Il dato diventa il fulcro introno al quale costruire alleanze (perché, come abbiamo visto nei punti precedenti, maggiori sono i dati, migliori sono le performance delle soluzioni) che saranno sempre meno one-to-one e sempre più nella logica dell’ecosistema. Questa logica porterà inevitabilmente verso la periferia del mercato finanziario quelle realtà che non trovano la propria collocazione all’interno di un ecosistema.
- Si aprono nuovi dilemmi etici. Per mitigare i rischi sociali ed economici che l’AI potrebbe provocare (un mercato finanziario sempre più dipendente dagli algoritmi di autoapprendimento potrebbe “sfuggire di mano” inducendo speculazioni che possono mettere in pericolo interi paesi) è indispensabile la collaborazione tra molteplici istituzioni. Lo studio riporta testualmente: “Mentre i potenziali benefici dell’IA saranno sorprendenti, i suoi potenziali rischi per il benessere sociale ed economico sono troppo grandi per non essere affrontati”


Di seguito indichiamo alcuni dei più recenti articoli pubblicati da ZeroUno e altre testate del Gruppo Digital360 su AI e Finance
- Intelligenza artificiale e chatbot rendono più semplice il dialogo con la banca
- Chatbot: ecco quelli che stanno rivoluzionando il Finance
- Intelligenza Artificiale e Machine Learning trasformeranno le banche
- Prestiti online, i social possono causare il rifiuto del finanziamento: che c’è da sapere
Studi professionali
Gli studi professionali, dagli avvocati ai commercialisti ai notai, sono considerati un settore che sarà sempre più impattato da tecnologie di intelligenza artificiale non solo per automatizzare le attività di routinarie, ma anche per attività di media complessità, andando a sostituire il lavoro umano che, nella migliore delle ipotesi, potrà essere riqualificato per attività a maggior valore ma nella peggiore verrà estromesso dal settore fino ad arrivare alla scomparsa di alcune figure professionali oggi presenti in questi studi.
Riassumiamo brevemente alcune delle attività che potrebbero ottenere benefici dall’adozione di tecnologie di AI:
- revisione dei documenti e ricerche legali: software di AI possono migliorare l’efficienza dell’analisi dei documenti per uso legale, catalogandoli come rilevanti per un caso particolare o richiedendo l’intervento umano per ulteriori approfondimenti;
- supporto alla due diligence: effettuare la ricerca di informazioni per conto dei loro clienti con la “dovuta diligenza” è una delle attività più impegnative degli studi di assistenza legale; è un lavoro che richiede la conferma di fatti e cifre e una valutazione approfondita delle decisioni sui casi precedenti per fornire un efficace supporto ai propri clienti. Gli strumenti di intelligenza artificiale possono aiutare questi professionisti a condurre la loro due diligence in modo più efficiente;
- revisione e gestione dei contratti: gli avvocati del lavoro svolgono attività molto impegnative per rivedere i contratti di lavoro al fine di identificare eventuali rischi per i loro clienti; i contratti vengono rivisti, analizzati punto per punto per consigliare i propri clienti se devono firmarli o come eventualmente rinegoziarli; con l’ausilio di software di machine learning è possibile redigere il “migliore” contratto possibile;
- prevedere il risultato di un procedimento giudiziario: grazie a strumenti di intelligenza artificiale gli avvocati possono essere supportati nel fare previsioni sugli esiti di un procedimento giudiziario aiutando i clienti nella decisione se, per esempio, proseguire in una determinata causa;
- fornire informazioni di base ai clienti o potenziali clienti: i grandi studi di assistenza legale devono dedicare assistenti alla preliminare attività di front end per tutte quelle persone che pensano di poter avere bisogno di un avvocato, ma non sono sicure. L’utilizzo di chatbot basate su tecnologie di natural language processing (più o meno evolute quindi solo testuali o integrate con sistemi voce) possono supportare gli studi nella prima fase di risposta a queste richieste e per indirizzare il potenziale cliente al professionista più competente sul suo caso.
Ma veniamo ad alcuni esempi. Sebbene pubblicato un paio di anni fa (e in questo campo 2 anni sono quasi un’era geologica) lo studio Can Robots be Lawyers, realizzato da due economisti del MIT e della North Carolina School of Law, mostra che il 13% del lavoro di un avvocato potrà essere automatizzato: il modello illustrato nello studio è basato su algoritmi di machine learning che consentono di automatizzare le diverse attività del lavoro di uno studio legale (dalla gestione documentale all’analisi delle leggi, alla scrittura delle clausole di un contratto, due diligence, fino alla preparazione dei dibattimenti ecc.) facendo riferimento a due tipologie di istruzioni, una basata sui dati (che vengono “macinati” dall’algoritmo) e l’altra di tipo deduttivo.
La banca d’affari JP Morgan lo scorso anno stava sperimentando il software COntract INtelligence (COIN) che, in pochi secondi, dovrebbe essere in grado di leggere e interpretare accordi commerciali e contratti di prestito (sostituendo procedure che occupano oltre 360 mila ore di lavoro/anno degli avvocati della Banca): a oggi non è ben chiaro se il software è già stato messo in produzione, ma sicuramente rappresenta un indicatore importante di quello che può attendere i professionisti del settore.
E vari sono anche gli esempi per gli studi di commercialisti: H&R Block, società americana di consulenza fiscale e tributaria, ha stretto una collaborazione con IBM per l’utilizzo del sistema cognitivo Watson per automatizzare le attività relative alla dichiarazione dei redditi in modo che, analizzando tutta la normativa e le agevolazioni possibili, i propri clienti possano presentare la dichiarazione fiscalmente più conveniente.
Per quanto riguarda l’Italia, l’Osservatorio professionisti e innovazione digitale del Politecnico di Milano, pur registrando una crescita del 2,6% negli investimenti in tecnologie ICT (dati aprile 2018) rispetto all’anno precedente, rileva come siano ancora minoritari gli studi che hanno implementato tecnologie di frontiera come l’intelligenza artificiale (figura 8).
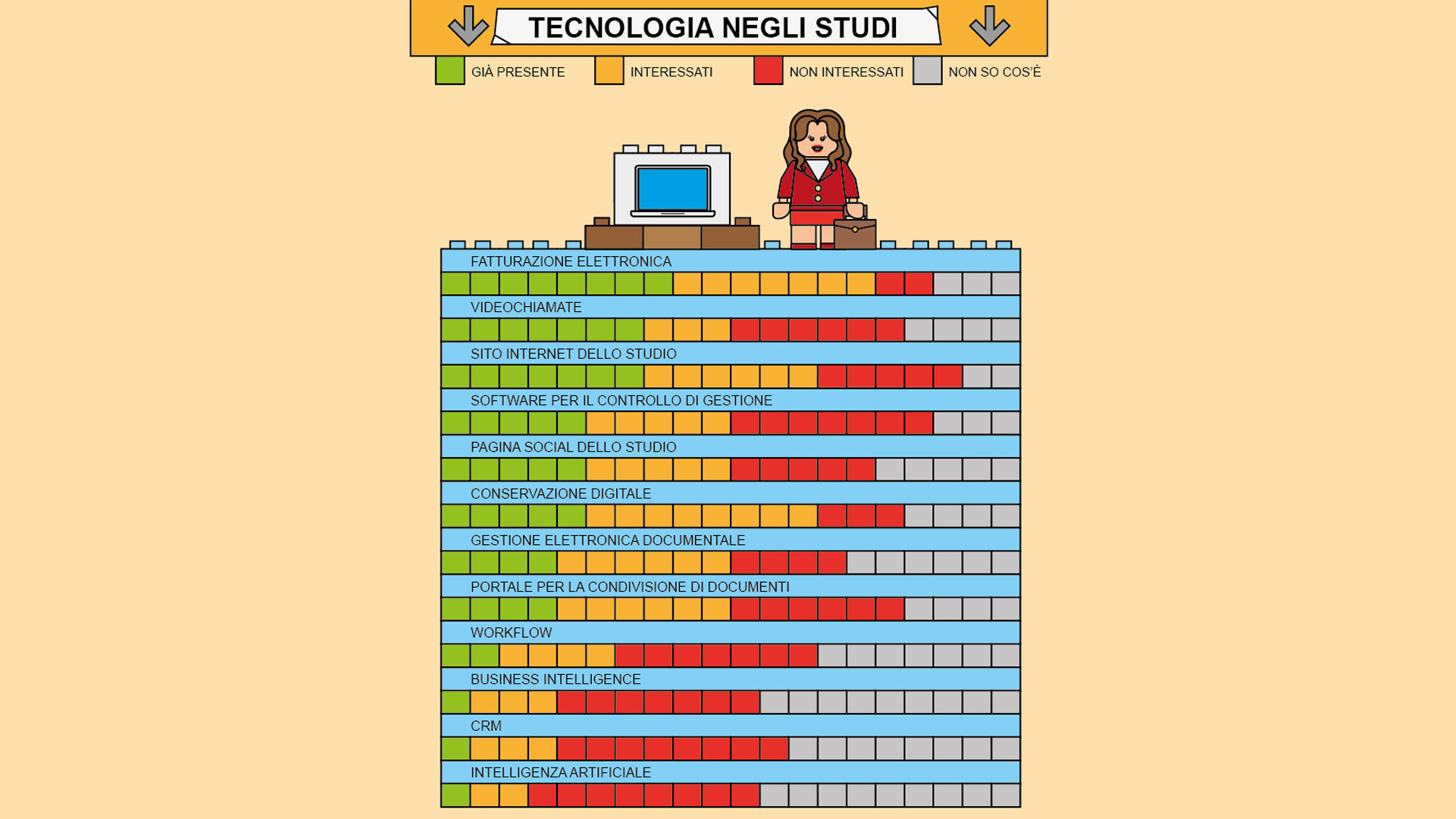
Fonte: Osservatorio professionisti e innovazione digitale del Politecnico di Milano, aprile 2018
Di seguito indichiamo alcuni dei più recenti articoli pubblicati da ZeroUno e altre testate del Gruppo Digital360 su AI e Studi Professionali
- Intelligenza artificiale negli studi professionali, l’impegno dei notai
- Intelligenza artificiale per avvocati e notai: rischi e opportunità
Manufacturing
Coming soon – A breve integreremo questo articolo con una parte dedicata alle applicazioni in ambito Manufacturing. Per essere informato quando questa parte verrà aggiornata iscriviti alla Newsletter di ZeroUno.
Smart city e pubblica amministrazione
Coming soon – A breve integreremo questo articolo con una parte dedicata alle applicazioni in ambito Smart city e pubblica amministrazione. Per essere informato quando questa parte verrà aggiornata iscriviti alla Newsletter di ZeroUno.
Agrifood
Coming soon – A breve integreremo questo articolo con una parte dedicata alle applicazioni in ambito Agrifood. Per essere informato quando questa parte verrà aggiornata iscriviti alla Newsletter di ZeroUno.
Energy
Coming soon – A breve integreremo questo articolo con una parte dedicata alle applicazioni in ambito Energy. Per essere informato quando questa parte verrà aggiornata iscriviti alla Newsletter di ZeroUno.
Media
Coming soon – A breve integreremo questo articolo con una parte dedicata alle applicazioni in ambito Media. Per essere informato quando questa parte verrà aggiornata iscriviti alla Newsletter di ZeroUno.
Arte
Coming soon – A breve integreremo questo articolo con una parte dedicata alle applicazioni in ambito Arte. Per essere informato quando questa parte verrà aggiornata iscriviti alla Newsletter di ZeroUno.
L’impatto dell’AI sul mondo del lavoro
Il tema dell’impatto sull’occupazione delle nuove tecnologie e, in particolare, di intelligenza artificiale e automazione suscita dibattiti accesi tra chi, da un lato, prospetta un futuro catastrofico con la perdita di migliaia di posti di lavoro e chi, sul versante opposto, minimizza questo aspetto ricordando che, in fondo, tutte le rivoluzioni hanno portato alla scomparsa di alcuni tipi di lavori per crearne di altri.
L’Osservatorio Artificial Intelligence del Politecnico di Milano, nel cercare di capire quale sarà l’impatto sull’occupazione di queste tecnologie, è partito da una prospettiva originale: dopo avere analizzato le dinamiche socio-demografiche del nostro paese, con una visione a 15 anni, le ha prima messe in relazione con la domanda e l’offerta di lavoro, analizzando a questo punto l’impatto dell’AI su uno scenario globale, e successivamente ne ha verificato l’impatto sul sistema previdenziale.
Per una visione approfondita rimandiamo all’articolo Lavoro e AI: “Più che una minaccia o un’opportunità, l’intelligenza artificiale è una necessità” e alla videointervista rilasciata dal Direttore dell’Osservatorio Giovanni Miragliotta. Qui ci limitiamo a fornire il dato finale emerso dall’indagine: a causa di diversi fattori, illustrati nell’articolo, nel 2033 in Italia mancheranno circa 4,7 milioni di posti di lavoro equivalenti; contemporaneamente si stima che le nuove tecnologie, in particolare intelligenza artificiale, automazione e robotica, sostituiranno 3,6 milioni di posti di lavoro equivalenti.
Quindi, secondo il Politecnico, ci troveremo con un disavanzo pari a circa 1,1 milioni di posti di lavoro, che potrà essere colmato grazie alla riduzione del tasso di disoccupazione, cosa che tuttavia impone un’azione di riconversione e formazione della forza lavoro non occupata. Un’analisi, quindi, che ribalta le previsioni catastrofiche su un impatto esclusivamente negativo dell’AI sul lavoro, ma che impone di iniziare a lavorare fin da subito (in primis nella formazione di nuove competenze) per essere pronti a rispondere a queste esigenze.
Le competenze necessarie per l’AI
Coming soon – A breve integreremo questo articolo con approfondimenti sulle competenze. Per essere informato quando questa parte verrà aggiornata iscriviti alla Newsletter di ZeroUno.
Intelligenza artificiale ed etica
Risulta evidente da tutto quanto abbiamo scritto finora che quello dell’intelligenza artificiale è un argomento molto delicato, che va a toccare l’etica che, in estrema sintesi, è proprio la capacità di distinguere i comportamenti corretti, leciti, giusti da quelli considerati scorretti, illeciti, ingiusti sulla base di un ideale modello comportamentale.
Prima di tutto, è corretto parlare di “intelligenza” artificiale? “Negli strumenti oggi disponibili non c’è nulla che assomigli, neanche lontanamente, anche solo all’intelligenza di un topo o di un cane. Quello che c’è è una grandissima capacità di risolvere problemi con successo, perseguendo un fine, che spesso è stato stabilito da un essere umano. Ecco quindi, per tornare alla sua domanda, che preferirei parlare di intelligenza aumentata, cioè che aumenta la nostra”, dice Luciano Floridi, professore ordinario di filosofia ed etica dell’informazione all’Università di Oxford nell’intervista rilasciata a ZeroUno (vedi AI ed etica: relazione delicata, ma cruciale. Intervista a Luciano Floridi)
Ma queste tecnologie consentono di affidare alle macchine delle scelte, e allora: quali potranno essere le conseguenze? Ma soprattutto, quali scelte possono essere affidate alle macchine?
“Vi sono nuove problematiche di etica applicata, relative ai temi della responsabilità individuale e collettiva, della dignità e dei diritti fondamentali delle persone, suscitate dagli attuali sviluppi dell’interazione uomo-macchina. Vi sono problemi ontologici relativi all’identità personale che riguardano gli interventi bionici volti a recuperare o potenziare le capacità sensomotorie e cognitive degli esseri umani. E vi sono problemi di epistemologia generale, che riguardano la nostra limitata capacità di prevedere il comportamento di robot e di agenti software dell’intelligenza artificiale”, scrive, come si riporta nell’articolo Riflessioni etiche su I.A. e robotica, Guglielmo Tamburrini docente di Logica e Filosofia della Scienza dell’Università di Napoli Federico II, insignito nel 2014 del Premio Internazionale Giulio Preti per studiosi che si sono distinti nell’aver coniugato scienza e filosofia.
“Sul tema della delega delle decisioni – prosegue Floridi – forse vale la pena distinguere tra delega di processi e delega di decisioni. Banalizzando, possiamo delegare il processo di lavare i piatti alla lavastoviglie, ma se e quando farlo, e che cosa metterci dentro è una decisione che rimane in capo a noi. Per quanto banale, questa logica è alla base di tutte le decisioni e i processi delegati alla tecnologia: quello che c’è dietro (perché, quando, cosa, vale la pena…) resta, deve restare, in capo a noi; il come (con quale efficacia, con quale efficienza…) è l’oggetto della delega. Questo è fondamentale: va bene la delega dei processi, seppur con le dovute verifiche; per la delega delle decisioni, attenzione, va valutata con moltissima cautela. E tutto questo lo dico con un certo ottimismo nei confronti di queste tecnologie”.
Un altro tema riguarda l’integrità dell’identità personale. Sono innegabili i passi avanti compiuti dalla bioingegneria e ci sono sistemi che consentono di leggere e utilizzare i segnali neurali associati all’attività cognitiva per controllare un arto artificiale, con indubbio beneficio per chi ha subito un’amputazione. “Queste ricerche bioniche – scrive ancora Tamburrini – si propongono soprattutto di ripristinare o di vicariare funzioni senso-motorie perdute, ma aprono la strada al potenziamento di apparati senso-motori e cognitivi che funzionano regolarmente. È opportuno chiedersi se sia nella nostra disponibilità modificare la nostra dotazione ‘naturale’ di capacità senso-motorie e cognitive attraverso interventi bionici. Una risposta positiva a tale quesito suscita a sua volta domande sulla persistenza dell’identità personale, prima e dopo l’intervento bionico. Più specificamente: una modifica delle funzioni mentali, sensoriali o motorie resa possibile dai sistemi bionici può indurre una modifica dell’identità personale?”.
Concludiamo questa breve riflessione sul rapporto tra intelligenza artificiale ed etica riportando quanto disse in un’intervista rilasciata qualche tempo fa Richard Hunter, Vp & Fellow Gartner, in un’intervista rilasciata a ZeroUno qualche tempo fa (vedi CISO: i nuovi rischi etici e legali del business digitale): “Si entra in una fase di rischio di tipo nuovo, etico e di conseguenza legale. Ogni macchina con capacità decisionale agisce con riferimento esplicito o implicito a un ‘sistema di valori’ (ossia gli algoritmi che le fanno agire) che universali non sono, anzi talora sono in conflitto. Insomma, i nuovi rischi del digital business non sono solo grandi, ma di nuovo genere”.
Intelligenza artificiale e giurisprudenza
I sistemi di intelligenza artificiale pongono nuovi e inaspettati problemi nel mondo del diritto e della società in generale. Ci troviamo davanti a nuove entità, le cui decisioni e risultati non sono pienamente l’effetto di azioni umane, ma derivano da una serie di processi che, dopo l’istruzione della macchina, hanno autonoma capacità decisionale e in alcuni casi non giustificabili a posteriori, in quanto non è possibile comprendere come il sistema sia giunto ad assumere una certa decisione. Di chi è dunque la responsabilità giuridica delle loro azioni? Quali sono gli ambiti più critici? Come si stanno muovendo, in ambito regolatorio, i paesi attivi nello sviluppo di sistemi di AI?
Massimiliano Nicotra ha approfondito gli aspetti specificatamente giuridici nell’articolo Intelligenza artificiale: gli aspetti etici e giuridici, del quale riportiamo alcuni spunti.
“Il tema dell’intelligenza artificiale non è nuovo al mondo del diritto e dell’etica. Parallelamente al confronto che nasceva nel settore della ricerca scientifica emergevano anche studi giuridici che si ponevano l’obiettivo di esaminare il funzionamento e le implicazioni di quelli che allora erano denominati “sistemi esperti”. Dagli anni ’90 e fino a quelli più recenti, il tema della regolazione dei sistemi di intelligenza artificiale non è stato più oggetto di analisi significative, fino a quando dal 2014 in poi, vari Paesi hanno cominciato ad occuparsi di questa tematica soprattutto interrogandosi sui presupposti per un utilizzo etico di queste tecnologie, contemporaneamente cercando anche di individuare un quadro giuridico nell’ambito dei vari sistemi, per la loro regolazione”.
L’avvocato analizza poi la situazione nei diversi paesi e i differenti approcci, sottolineando come “L’Unione Europea è stata comunque la prima a porsi il problema dell’intelligenza artificiale non solo dal punto di vista etico (ottica già seguita dal Regno Unito nel 2016), ma anche regolatorio soprattutto dal punto di vista dei meccanismi di imputazione delle responsabilità in ambito civile.
Nella Risoluzione del Parlamento del 16 febbraio 2017 recante raccomandazioni alla Commissione Europea concernenti norme di diritto civile sulla robotica, in cui sono presi in considerazione anche i sistemi di intelligenza artificiale, il Parlamento europeo aveva già indicato come temi di attenzione quelli relativi ai risvolti etici e sociali, sottolineando che lo sviluppo della robotica e dell’intelligenza artificiale dovrebbe mirare a integrare le capacità umane e non a sostituirle.
La citata Risoluzione, pur essendo tesa a fornire delle linee guida in ambito civilistico, offre numerosi spunti che consentono di comprendere l’ampiezza delle problematiche giuridiche e sociali che l’intelligenza artificiale porta con sé.
Dal punto di vista della responsabilità degli agenti intelligenti, la sfida sorge nel momento in cui consideriamo che il criterio tradizionale di imputabilità è collegato a una condotta da parte del soggetto agente (un’intelligenza artificiale pone in essere una sua autonoma condotta nel mondo fisico?). I sistemi di intelligenza artificiale sembrano però richiamare i principi della responsabilità del produttore, che però devono adeguarsi al fatto che tali sistemi assumono capacità decisionale autonoma, e potrebbero coinvolgere anche soggetti diversi dal solo produttore, quali i programmatori o coloro che hanno realizzato gli algoritmi decisionali. Un ulteriore criterio di imputazione della responsabilità potrebbe essere anche rinvenuto nella culpa in vigilando di colui che utilizza il sistema, nel momento in cui può rendersi conto dell’adozione di decisioni errate da parte dello stesso.
Il documento del Parlamento Europeo elenca una serie di punti di attenzione e anche suggerimenti per arrivare a una corretta soluzione normativa degli stessi”.
L’autore conclude l’articolo affrontando, dal punto di vista giuridico, alcuni casi specifici: AI e concorrenza, AI e diretto d’autore, AI e armi letali, AI e auto a guida autonoma, AI e mercato finanziario, AI e riconoscimento facciale, AI e mercato del lavoro, AI e Sanità.
I migliori libri sull’intelligenza artificiale
Essendo il tema del momento sono tantissimi i libri sull’intelligenza artificiale. Ne abbiamo fatto una piccola selezione che arricchiremo man mano.

Vita 3.0. Essere umani nell’era dell’intelligenza artificiale
Max Tegmark, Cortina Raffello Editore, 2018, p. 452
Svedese di nascita e americano d’adozione, Max Tegmark è uno dei più noti e discussi fisici teorici viventi. È tra i fondatori del Future of Life Institute e tra gli organizzatori del meeting internazionale ad Asilomar, nel quale viene redatto un documento condiviso di 23 punti I Principi di Asilomar per l’intelligenza artificiale, che propone delle linee guida per lo sviluppo di un’intelligenza artificiale benefica dai problemi della ricerca ai problemi di lungo termine attraverso gli aspetti etici e di valori sociali. Il libro cerca di rispondere ad alcune domande topiche: in che modo l’intelligenza artificiale influirà su criminalità, giustizia, occupazione, società e sul senso stesso di essere umani? Come possiamo far crescere la nostra prosperità grazie all’automazione senza che le persone perdano reddito o uno scopo? Quali consigli dobbiamo dare ai bambini di oggi per la loro futura carriera lavorativa? Dobbiamo temere una corsa agli armamenti con armi letali autonome? Le macchine alla fine ci supereranno sostituendo gli umani nel mercato del lavoro? L’intelligenza artificiale aiuterà la vita a fiorire come mai prima d’ora o ci darà un potere più grande di quello che siamo in grado di gestire?
 Le macchine sapienti. Intelligenze artificiali e decisioni umane
Le macchine sapienti. Intelligenze artificiali e decisioni umane
Paolo Benanti, Marietti, 2018, p. 160
Padre Paolo Benanti, frate francescano e docente di teologia morale ed etica delle tecnologie nonché membro del Gruppo di esperti di alto livello insediatosi presso il ministero dello Sviluppo economico, riflette sulle sfide etiche e sociali che l’innovazione porta con sé. L’autore, noto a livello internazionale nell’ambito della bioetica e del dibattito sul rapporto tra teologia, bioingegneria e neuroscienze, guarda con favore alla diffusione delle “macchine sapienti” e ragiona sul fatto che i processi innovativi hanno valenza positiva solo se orientati a un progresso autenticamente umano che si concretizzi in un sincero impegno morale dei singoli e delle istituzioni nella ricerca del bene comune.

Intelligenza artificiale. Guida al futuro prossimo
Jerry Kaplan, Luiss University Press, 2018, p. 242
Esperto di intelligenza artificiale, imprenditore e innovatore, Jerry Kaplan è stato co-fondatore di quattro startup della Silicon Valley. Autore di bestseller, è docente al Fellow del Center for Legal Informatics alla Stanford University e professore presso il dipartimento di Computer Science della stessa università. In questo libro l’autore si presta a farci da guida attraverso i tanti aspetti tecnologici, economici e sociali dell’intelligenza artificiale, scomponendo i concetti di robot, machine learning e lavoro automatizzato, delineando incredibili scenari del nostro futuro più prossimo.